Hallo Hexi,
ich hole mal etwas aus und versuche es zu erklären. 
Zitat:
Original erstellt von Hexi:
... wir importieren unseren Artikelstamm aus einem SAP System. Dort legen wir alle Artikel in mind. zwei Sprachen DE/EN an. Jetzt habe ich somit immer zwei Sprachen die ich in die Artikelstücklsite importieren könnte, aber wie ich das hier so verstehe geht das gar nicht.
Wenn euer System die gewünschten Artikel in eine
CSV-Datei schreiben kann gehen deine Wünsche in Erfüllung ;)
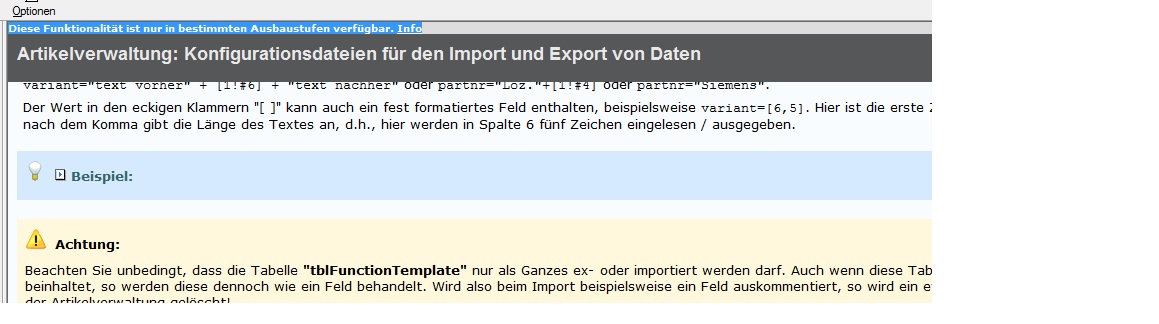
Hierzu musst du dir eine Konfigurationsdatei erstellen in der der genaue Aufbau der CSV-Datei beschrieben ist. Schau dir am besten die mitgelieferte csvimportexport.cfg Konfigurationsdatei mal an. Sie befindet sich im allgemeinen im Pfad $(EPLAN_DATA)\Artikel\Kundenkennung.
Wir erstellen unsere CSV-Dateien immer so das jeder Datensatz komplett in einer Zeile steht. Als Seperator verwenden wir ein TAB und kein Textquote.
Zitat:
Original erstellt von Hexi:
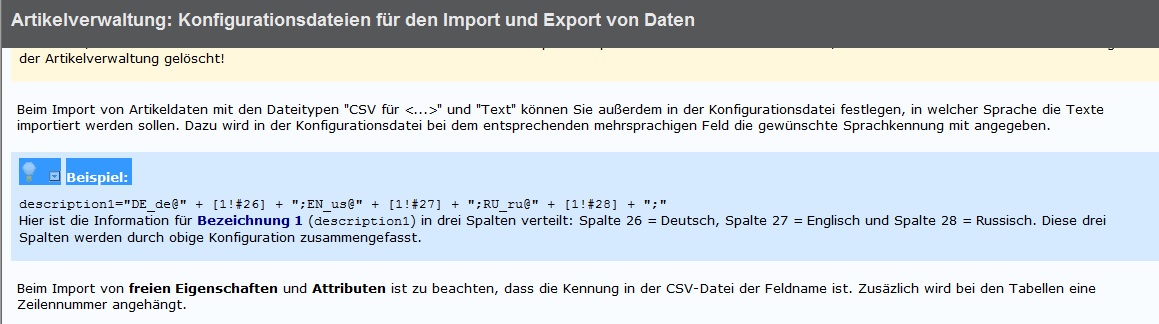
Deswegen meine Frage , wofür ist dann der Import in der csv :"description1="DE_de@" + [1!#26] + ";EN_us@" + [1!#27] + ";RU_ru@" + [1!#28] + ";"
Wo ich mehrere Sprachen importieren kann. Wo werden die Sprachen den abgelegt? Eigentlich hatte ich die Höffnung unsere Übersetzungsdatei nicht auch nocht mit 9000 Artikelübersetzungen zu befüllen.
Eplan erwartet zum Import im Idealfall übersetzte Texte immer als ein Feld. Der Aufbau folgt diesem Muster. Es beginnt mit der Sprachkennung z. B. de_DE gefolgt von einem at @ und dem Text mit abschließenden Semikolon. Jede weitere Sprache wird nach dem gleichen Muster drangehangen. Also direkt hinter das Semikolon wieder die Sprachkennung z. B. en_US gefolgt von einem at @ und dem Text mit abschließenden Semikolon usw.
Code:
de_DE@Hilfsschütz;en_US@Auxiliary contactor;fr_FR@Contacteur auxiliaire;
Wahrscheinlich wird aber euer System beim Export der Artikeldaten jede Sprache in ein eigenes Feld (Spalte) schreiben. Zusätzlich mit einem Feldtrenner → dazwischen.
Code:
Hilfsschütz→Auxiliary contactor→Contacteur auxiliaire
Mit Hilfe der Konfugurationsdatei werden diese einzelnen Felder des Datensatzes während des Imports dann so zusammengesetzt wie es der erste Codeschnipsel zeigt. Die unten aufgeführten Zeile ist eigentlich eine Strig-Operation mit der z. B. die drei Sprachen so zusammengesetzt werden das Eplan sie dem Beschreibungsfeld 1 zuordnen kann.
Code:
description1="de_DE@"+[1!#2]+";en_US@"+[1!#3]+";fr_FR@"+[1!#4]+";"
In der eckigen Klammer bedeutet die
1! das sich das Feld in der ersten Zeile des Datensatzes befindet. Die Angabe der Spalte wird durch
#2 angegeben.
Zum Beispiel könnte ein einfacher Datensatz in deiner Datei wie folgt so aufgebaut sein. Als Feldtrenner (Separator) habe ich ein TAB → dargestellt.
Code:
SIE.3RH1122-1BB40→Hilfsschütz→Auxiliary contactor→Contacteur auxiliaire
Dann müsste die Konfigurationsdatei etwa so aussehen.
Code:
; Spaltentrenner - Seperator (eingestellt ist TAB)
separator=→
;
; Texterkennungszeichen. Dies kann leer sein, dann darf der Spaltentrenner
; niemals im Text erscheinen. Deshalb wurde als Spaltentrenner ein TAB
; eingetragen. Das dürfte in den Datenfeldern selbst nicht vorkommen.
textquote=
;
; Titelzeile, es wird als Titel das ausgegeben was hinter dem = steht.
; Muss aber in skipLeadIn berücksichtigt werden.
; Ist für den eigenen Export wichtig.
;header=
;
; Bei fieldTitle=1 werden die Namen der Felder als Spaltenkopf mit ausgegeben.
; Muss aber in skipLeadIn berücksichtigt werden.
; Ist für den eigenen Export wichtig.
;fieldTitle=
;
; skipLeadIn muss alle header includieren, d.h. fieldTitle generiert eine
; Titelzeile, und header ebenso, also mindestens 2!
skipLeadIn =0
;
; Zeilen für einen Datensatz.
rowsPerRecord = 1
;
; Definieren Sie trim=1, damit beim Import Leerzeichen vor und hinter dem eigentlichen Text entfernt und der Text
; linksbündig in das EPLAN-Datenfeld übernommen wird.
trim=1
;
; Regionsabhängige Zahlenformate. Das Zahlenformat des Rechners wird verwendet, um diese einzulesen.
; Beim Export wird es ignoriert.
; Werte: 0: Der Dezimaltrenner darf , oder . sein; 1: das regionsabhängige Zahlenformat.
convert-region-dependent=0
;table=tblPart ; Tabelle Einzelteile
; class=[1!#??] ; Datensatztyp "1" = Einzelteil, "4" = Baugruppe
partnr=[1!#1] ; Eplan Artikelnummer
description1="de_DE@"+[1!#2]+";en_US@"+[1!#3]+";fr_FR@"+[1!#4]+";"
Alle Texte, incl. der Übersetzungen, landen nur in der Artikeldatenbank. Dein Wörterbuch wird nicht gefüllt.
Zitat:
Original erstellt von Hexi:
Wie machen das den die anderen P8Žler hier mit Fremdsprachenstücklisten? 
Also wir machen es wie oben beschrieben. Zwar nicht SAP aber unser System erzeugt eine Übergabedatei CSV und die wird dann importiert. Ebefalls mit allen Sprachen. Eplan typische Daten (Funktionsschablone usw.) werden in Eplan zu gepflegt.
Ich hoffe meine Ausführungen sind nicht über das Ziel hinaus geschossen. Wichtiger natürlich das sie auch verständlich sind
Gruß
Holger
Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP

 Foren auf CAD.de (alle Foren)
Foren auf CAD.de (alle Foren)

 |
| 


 .
.