|
Autor
|
Thema: Auftragsfreigabe programmieren - Anfängerfrage (1557 / mal gelesen)
|
JAKO95
Mitglied
Student
   Beiträge: 2
Registriert: 20.06.2018
|
 erstellt am: 20. Jun. 2018 16:18
erstellt am: 20. Jun. 2018 16:18  <-- editieren / zitieren --> <-- editieren / zitieren -->   Unities abgeben: Unities abgeben:          
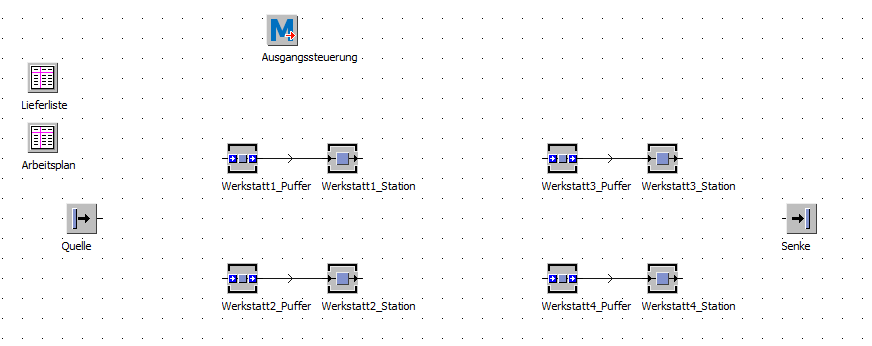
Hallo liebe Leute, ich bin Jan und studiere an der TU Dortmund. Im Rahmen eines Master Seminars muss ich einen LUMS Auftragsfreigabemechnismus in einer Werkstattfertigung programmieren. Zum Modell (Screenshot in der Anlage):
- Werkstattfertigung mit einem Puffer vor jeder Werkstatt (insgesamt 4 Werkstätten)
- 64 Aufträge sind bereits in dem Modell angelegt Die Freigabe soll nach dem folgenden periodischen/kontinuierlichen Muster erfolgen:
If Freigabezeitpunkt erreicht:
- Prüfe Kapazität
- Wenn genug Kapazität, dann Auftrag mit dringlichstem Due Date freigeben
- ansonsten weiter prüfen
Else (wenn perioderischer Freigabezeitpunkt nicht erreicht):
- Prüfe ob WIP an Maschine j unter bestimmter Grenze x liegt
- Dann Auftrag mit dringlichsten Due Date an dieser Maschine freigeben, wenn sie im Routing an erster Stelle steht Vielleicht hat jemand einen Ansatz wie man diese Auftragsfreigabe mit Hilfe von Methoden programmieren kann?
Vor jedem Puffer/Maschine der jeweiligen Werkstatt soll ein Sortierer eingebaut werden, der die Aufträge nach ihren Due Dates sortiert. Ich bin über jede Hilfe froh!
Vielen Dank! Viele Grüße
Jan Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP |
nadin1223
Mitglied
Ing.
Beiträge: 949
Registriert: 29.03.2016
|
erstellt am: 20. Jun. 2018 23:32 <-- editieren / zitieren --> Unities abgeben: Nur für JAKO95 
Hallo Jan, Mehrere Lösungswege sind möglich. Beispielsweise für "If Freigabezeitpunkt erreicht"
ist der Informationsfluss ähnlich den Materialfluss abbildbar. Also Station erzeugt Auftrag als BE. BEs haben Attribute: "DueDate" (time) und "Prozess" (table und Station im Index als Object). Mithilfe eines Sortierers wird beim Eintritt nach "DueDate" sortiert. Mit Generator wird auf diesen Sortierer zugegriffen und in einer For-Schleife die Aufträge geprüft, ob Produktion möglich. Wenn möglich erzeuge BE im Puffer vor Station und lösche den Auftrag aus sortierer. Das wäre die Methode1. (Diese Informationsverarbeitung kann auch feiner granuliert werden) Für deinen "Else"-Teil kann beispielsweise die Ausgangssteuerung in Werkstattstationen eine Methode2 aufrufen, die wie Methode1, die Aufträge prüft falls in Puffer die AnzahlBE=0, dann prüfe ob Auftrag existiert, wo Attribut "Prozess" auf [1,1] ist....(hier vielleicht auch die Zeitspanne prüffen, sodass die Aufträge, die in sechs Monaten fertig sein sollten, morgen an der Maschine nicht produziert werden.) Das wäre Methode2 vG
Nadin
------------------
Die einfachste Art an korrekte Informationen zu gelangen ist, etwas Falsches in ein Forum zu posten und auf die Korrektur zu warten. Matthew Austern Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP |
JAKO95
Mitglied
Student
Beiträge: 2
Registriert: 20.06.2018
|
erstellt am: 22. Jun. 2018 17:59 <-- editieren / zitieren --> Unities abgeben:
Die Idee mit dem Generator war super! Der erste Schritt von ziemlich vielen ist gemacht. Ich möchte ja wenn der Generator die Methode aktiviert gucken, ob genug Kapazität im System ist. Falls ja, sollen die Aufträge mit der höchsten Priorität freigegeben werden, solange noch genügend Kapazität vorhanden ist. Das heißt, die Methode müsste eine while Schleife sein, die solange läuft, wie Kapazität vorhanden, richtig? Wie kann ich dann mit der Methode auf die Aufträge in dem Sortierer zugreifen, sodass ich immer den ersten freigeben, also auf die nächste Maschine im Arbeitsplanumlagern kann, wenn die Kapazitätsbedingung erfüllt ist? Dann ist im Moment der WIP (Work in Process) als globale Variable definiert, damit
alle Methoden darauf zugreifen und aktualisieren können.
Die Frage ist nun: Wie bestimme ich den indirekten WIP? Rein verbal würde für Maschine 1 gelten: - Summe der Bearbeitungszeiten für Maschine 1 aus den sich im Puffer 1 befindenden
Aufträgen
- auf den anderen Maschinen prüfen, ob die Aufträge auf der jeweiligen Maschine und
dessen Puffer noch auf Maschine 1 müssen, dann die Bearbeitungszeit des Auftrags mit
einem Prozentsatz der abhängig von der Position von Maschine 1 im Arbeitsplan ist
multiplizieren.
--> Bsp.: Auftrag 10 ist im Puffer vor Maschine 2 und muss als nächstes auf Maschine
1. Dann würde 50% der Bearbeitungszeit von Auftrag 10 auf Maschine 1 für den WIP von
Maschine 1 berechnet. Wäre Maschine 1 erst als übernächstes dran, würde die
Bearbeitungszeit mit 33% berechnet und so weiter.
Hat vielleicht jemand von Euch einen Ansatz wie man auf die Aufträge zugreift, dann
guckt, welche Maschine im weiteren Arbeitsplan steht und an welcher Position die
hinter der aktuellen ist? Danke!!! Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP |

| | Enterprise Account Executive - Manufacturing / SaaS (m/w/d) | | Wenn du schon mal eine CAD-Zeichnung gesehen hast und dachtest: ?Da steckt doch mehr drin als nur Linien und Maße?, dann wirst du dich bei uns schnell zu Hause fühlen. Denn genau das glauben wir auch! Wir arbeiten jeden Tag daran, dieses ?Mehr? sichtbar zu machen. PartSpace ist die Plattform, die technischen Zeichnungen eine neue Bedeutung gibt: Unsere KI analysiert, versteht und rechnet aus, was früher Bauchgefühl war.... | | Anzeige ansehen | Feste Anstellung |
|
nadin1223
Mitglied
Ing.
Beiträge: 949
Registriert: 29.03.2016
|
erstellt am: 22. Jun. 2018 21:42 <-- editieren / zitieren --> Unities abgeben: Nur für JAKO95
Zitat:
Das heißt, die Methode müsste eine while Schleife sein, die solange läuft, wie Kapazität vorhanden, richtig?
while oder for...ja gehe solange die Aufträge durch, bis Zielwert erreicht. Zitat:
Wie kann ich dann mit der Methode auf die Aufträge in dem Sortierer zugreifen, sodass
ich immer den ersten freigeben, also auf die nächste Maschine im Arbeitsplanumlagern
kann, wenn die Kapazitätsbedingung erfüllt ist?
z.B. current.sortierer.BE(current.sortierer.anzahlbes) <-- das ist das letzte BE auf dem Sortierer. Das wird als letztes umlagern current.sortierer.BE(1) <-- das ist das erste BE auf dem Sortierer. Das wird als erstes umlagern. Oder habe ich die Frage falsch verstanden?
Zitat:
- Summe der Bearbeitungszeiten für Maschine 1 aus den sich im Puffer 1 befindenden
Aufträgen
Schreibe die Summe in Puffer als lokale Variable (Attribut), + bei einlagern, - bei auslagern (schleifen kosten Zeit) und das gleiche auch für die Variable die mit 50% und 33% gerechnet werden soll, sodass jede Ressource ihre Belastung kennt. Dann kannst du die Ressorucenbelastung mit Auftragsdaten vergleichen. Wenn Station die gewichtete Belastung ablehnt, dann Schleife verlassen und nächster Auftrag...bis Aufträge zu weit in der Zukunft liegen. TIPP:
Stell dir vor, du wärst der Produktionsleiter oder Meister in dieser Produktion. Wann schaut wer den Auftrag an? Was weiß wer wieviel an Station/ in Fertigungssteuerung / von IE ..
------------------
Die einfachste Art an korrekte Informationen zu gelangen ist, etwas Falsches in ein Forum zu posten und auf die Korrektur zu warten. Matthew Austern Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP |
| Anzeige.:
Anzeige: (Infos zum Werbeplatz >>)
 |

 Foren auf CAD.de
Foren auf CAD.de

 |
|