| | |
 | KISTERS 3DViewStation-Integrationen für Siemens Teamcenter und Active Workspace sind ab sofort verfügbar, eine Pressemitteilung
|
|
Autor
|
Thema: Maximalwerte ausgeben (3511 mal gelesen)
|
aup
Mitglied
   Beiträge: 82
Registriert: 16.08.2007
|
 erstellt am: 22. Jan. 2010 14:59
erstellt am: 22. Jan. 2010 14:59  <-- editieren / zitieren --> <-- editieren / zitieren -->   Unities abgeben: Unities abgeben:          
Wieder mal ich, hallo, ich bin leider noch nicht so fit in python, deswegen muss ich euch bemühen...
Danke im Voraus.
Ich möchte aus 243 ODBs die maximalwerte verschiedener (immer gleich benannter) Instances auslesen.
(var_001.odb, var_002.odb, ..., var_243.odb) Am liebsten wäre es mir, wenn man die Daten in eine txt schreibt und am besten gleich mit jeder neu augewerteten ODB eine Zeile angehängt wird. Zweite Geschichte ist eine for-Schleife für meine Dateinamen.
(var_001.cae... siehe oben)
Ich will immer die CAEs nacheinander öffnen und immer wieder einen Befehl (submit...) ablaufen lassen.
Habe es momentan sehr konventionell gelöst ohne Schleife... demzufolge ist das Skript ellenlang.
Das geht doch sicherlich eleganter... aber wie bekomme ich die Schleife in meinen Dateinamen ;-) Danke erstmal ich muss mal weiter rotieren...
------------------
Unser Wissen ist ein Tropfen, was wir nicht wissen, ist ein Ozean.
Isaac Newton (1643-1727) Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP |
Mustaine
Ehrenmitglied V.I.P. h.c.
Beiträge: 3585
Registriert: 04.08.2005 Abaqus
|
 erstellt am: 25. Jan. 2010 11:04 <-- editieren / zitieren --> Unities abgeben: Nur für aup
erstellt am: 25. Jan. 2010 11:04 <-- editieren / zitieren --> Unities abgeben: Nur für aup 
Zu Problem 1: Du findest ein sehr ähnliches Beispiel im Scripting Users Manual 9.10.1 Finding the maximum value of von Mises stress
Zu Problem 2:
Das dürfte nicht schwer sein. Du liest mit Python die Namen aller Dateien im Verzeichnis und speicherst sie in einer Liste. Danach iterierst du über die Liste und erzeugst eine neue Liste, wenn die Dateien einen bestimmten Namen haben oder eine bestimmte Endung.
Über diese neue Liste kannst du nun iterieren und die Kommandos ausführen.
Ich habe das mal mit Input-Dateien (.inp) gemacht. Hier der entsprechende Abschnitt:
Code:
import osinputs = [] #Alle Dateien aufsammeln
pfad = os.getcwd()
dateiliste = os.listdir(pfad) #Dateien mit bestimmter Endung finden und in Liste schreiben
for datei in dateiliste:
if datei.endswith('.inp'):
inputs.append(datei)
#Ueber Liste iterieren
for name in inputs:
:
:
Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP |
aup
Mitglied
Beiträge: 82
Registriert: 16.08.2007
|
erstellt am: 26. Jan. 2010 08:32 <-- editieren / zitieren --> Unities abgeben:
Erstmal vielen Dank, habe gestern herumprobiert, aber keinen Erfolg gehabt.
Das Skript des UserManuals kann ich noch nicht komplett lesen und verstehen, d.h. ich weiß nicht, was das macht.
Außerdem ist bei mir ABAQUS abgeschmiergelt, als ich es laufen lassen wollte. Mit deinem Vorschlag komme ich auch nicht ganz zurecht.
Was kommt bei
inputs =[] hin... ein Verzeichnispfad? Für weitere Hinweise wäre ich sehr dankbar... ------------------
Unser Wissen ist ein Tropfen, was wir nicht wissen, ist ein Ozean.
Isaac Newton (1643-1727) Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP |
Mustaine
Ehrenmitglied V.I.P. h.c.
Beiträge: 3585
Registriert: 04.08.2005 Abaqus
|
erstellt am: 26. Jan. 2010 14:23 <-- editieren / zitieren --> Unities abgeben: Nur für aup
Mit inputs=[] wird einfach nur eine leere Liste erzeugt, die dann mit inputs.append(datei) gefüllt wird.
Ansonsten wirst du nicht darum herum kommen ein wenig Python zu lernen um das Script zu verstehen. Im Prinzip ist es auch nicht schwer. Die Hauptarbeit des Scripts liegt im Abschnitt unten.
- es wird über alle Steps iteriert
- es wird über alle Frames je Step iteriet
- es wird über alle Elemente in dem gewünschten Set iteriert
Code:
for step in odb.steps.values():
print 'Processing Step:', step.name
for frame in step.frames:
allFields = frame.fieldOutputs
if (allFields.has_key(Stress)):
isStressPresent = 1
stressSet = allFields[Stress]
if elemset:
stressSet = stressSet.getSubset(
region=elemset)
for stressValue in stressSet.values:
if (stressValue.mises > maxMises):
maxMises = stressValue.mises
maxElem = stressValue.elementLabel
maxStep = step.name
maxFrame = frame.incrementNumber
Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP |
aup
Mitglied
Beiträge: 82
Registriert: 16.08.2007
|
erstellt am: 27. Jan. 2010 11:14 <-- editieren / zitieren --> Unities abgeben:
Hallo, es sieht gut aus, aber ich bekomme diese Problem nicht hin.
Nachdem ich mit Dateinen erzeugt habe, die zum einen
die ODB-Dateinamen enthalten und zum anderen die Variantennamen (ODB-Dateinamen ohne '.odb')
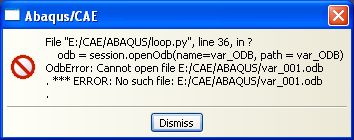
kann ich die bestimmte odb nicht einlesen habe das abgespeckte Skript angehängt. for x in range(1,244,1):
variante = varianten_datei.readline()
var_ODB = var_ODB_datei.readline()
odb = session.openOdb(path = var_ODB) hier kommt eine Fehlermeldung
TypeError: not all required arguments specified; expected 1, got 0 gebt mir bitte einen Tip, mir steht das wasser bis zum hals... ciao, und vielen Dank im Voraus.
aup ------------------
Unser Wissen ist ein Tropfen, was wir nicht wissen, ist ein Ozean.
Isaac Newton (1643-1727) Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP |
loretta
Mitglied
Beiträge: 17
Registriert: 31.10.2008
|
erstellt am: 27. Jan. 2010 16:24 <-- editieren / zitieren --> Unities abgeben: Nur für aup
Hallo, die Zeile, die bei dir den Fehler erzeugt muss korrekt lauten:
odb = session.openOdb(name=var_ODB, path = var_ODB) Grund für den Fehler: Die Methode session.openOdb will auf JEDEN FALL ein Argument mit dem Namen "name" sehen, das Argument "path" ist optional. Daher die kryptische Fehlermeldung in der der Interpreter behauptet, er hätte ein Argument zu wenig. Grüße
Patrick Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP |
aup
Mitglied
Beiträge: 82
Registriert: 16.08.2007
|
erstellt am: 27. Jan. 2010 17:12 <-- editieren / zitieren --> Unities abgeben:
hallo, na das kling schon mal gut, allergings kommt immer noch eine Fehlermeldung. Ich denke das kommt von den Befehlen variante = varianten_datei.readline() var_ODB = var_ODB_datei.readline() die sollen nach und nach die in einer Datei erzeugten Namensliste abfragen. Ich denke nur, dass hier der "Wagenrücklauf" - sprich "Return" stört. Meine Ausgabe-Datei weist diese Phänomene auf, ich will alles auf einer zeile ausgeben und die "variante", die abgefragt wird, steht auf Zeile x und die Ergebnisse auf Zeile x+1. Dies führt warscheinlich dazu, dass die odb.Datei nicht korrekt bei dem Befehl openOdb verwendet wird. Vorschläge... ich bin total offen dafür ;-) Verwende ich den Befehl readline() falsch? Danke für euer Mitdenken...
Ich versprechs, ich arbeite mich weiter in Python ein... ------------------
Unser Wissen ist ein Tropfen, was wir nicht wissen, ist ein Ozean.
Isaac Newton (1643-1727) Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP |
loretta
Mitglied
Beiträge: 17
Registriert: 31.10.2008
|
erstellt am: 27. Jan. 2010 17:39 <-- editieren / zitieren --> Unities abgeben: Nur für aup
Moin, hmm, könnte schon sein, dass daher der Fehler rührt. Kann es hier gerade nicht ausprobieren, aber erweiter deine Zeile doch mal so: variante = varianten_datei.readline().rstrip('\n')
var_ODB = var_ODB_datei.readline().rstrip('\n') Die Funktion rstrip([char]) entfernt alle übergebenen Zeichen, die am rechten Rand des Strings stehen. Deine readline() Verwendung ist schon ok. Gruß
Patrick Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP |
aup
Mitglied
Beiträge: 82
Registriert: 16.08.2007
|
erstellt am: 27. Jan. 2010 17:50 <-- editieren / zitieren --> Unities abgeben:
JUHUUUUUU, es funzt!
Ich könnt dich Küssen...
Danke nochmal...
das ganze hat mich knappe zwei tage gekostet und bewahrt mich vor tagelanger stupider stumpfsinniger Arbeit. ciao, Andreas ------------------
Unser Wissen ist ein Tropfen, was wir nicht wissen, ist ein Ozean.
Isaac Newton (1643-1727) Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP |
aup
Mitglied
Beiträge: 82
Registriert: 16.08.2007
|
 erstellt am: 29. Jan. 2010 08:20 <-- editieren / zitieren --> Unities abgeben:
erstellt am: 29. Jan. 2010 08:20 <-- editieren / zitieren --> Unities abgeben:
Hallo, noch eine kleinigkeit, um mein Skript "schön" zu machen!!! falls die erzeugten Dateien
- var_ODB.txt
- varianten.txt
- auswertung.txt
schon bestehen, und meine neu gefüllte Zeilen den Inhalt nicht vollständig üüberschreiben, würde ich ja alte Werte mit in Excel importieren. kann man den Dateiinhalt auch löschen, bevor man ihn neu vollschreibt. alternativ, vie sieht der Code aus, wenn ich "append" nutzen will?
habe schon bisschen mit dem Syntax rumgespielt, aber noch keinen Erfolg gehabt. Danke euch... ------------------
Unser Wissen ist ein Tropfen, was wir nicht wissen, ist ein Ozean.
Isaac Newton (1643-1727) Eine Antwort auf diesen Beitrag verfassen (mit Zitat/Zitat des Beitrags) IP |

 Foren auf CAD.de
Foren auf CAD.de

 |
|